Python入門④Twitter APIでツイート解析!単語をWordCloudで画像化
アニメーションするWord Cloud、画像マスクのやり方。
Twitter APIで、話題のキーワードを含むツイートを一気に取得する方法など。
昨日は選挙でしたね。投票は行かれましたか~
前回は、有名人の方々のツイートを集めたものを形態素解析して、それをWord Cloudで見える化する、というのをやりました。
今回は、Word Cloudの応用編で、マスク画像の適用をやってみたいと思います。
Word Cloudに画像マスクを適用する

こんなイメージです。用意した画像でワードをかたどって出力します。
Pythonを使うには?
Pythonを使うための準備から実行方法までは、下記を順番に参照なさってください。
①Pythonのインストール

②pipのインストール

pipのインストール - hatebcustom
Pythonプログラム入門の1回目です。 Webスクレイピングにより、指定したURLから画像ファイルのみを抽出して自分のパソコンにダウンロードします。
③プログラムの実行
Twitter APIの使い方については、こちらに詳しく解説されています。
またこの記事でも触れていますので、参考になさってください。

Twitter APIでツイートを収集
まず、Word Cloudで使うワードを用意します。Twitter APIを利用して、指定したキーワードでツイートを収集します。
Twitter APIでのツイート取得は1度に200件までという制限がありますが、こちらで紹介されているコードは制限解除までプログラムの処理をスリープさせ、解除後に処理を再開させるという方式で、一気に3000件まで取得することができます。
コード7区さんの上記記事を参照させていただき、仕様を少し変えて利用しました。一応、変更したコードのリンクを貼っておきます。
- コードを確認する(tweetlot.py)
指定したキーワード、もしくはスクリーンネーム(ユーザーID)のツイートを一度に1000件取得して、テキストファイル(tweets.txt)に保存します。
コードを使うにあたり変更する箇所
10~13行目の「Consumer API Keys」、「アクセストークン情報」
237行目の'はてなブログ'の部分を収集したいツイートに含まれるキーワードに
240行目の'heureux_yoppy'の部分を収集したいスクリーンネーム(ユーザーIDの@からうしろの部分)に
244行目のtotal=1000の部分を一度に取得したい数値に
このあたりを自由に変更してご利用ください。
※237行目と240行目の部分は、どちらかをコメントアウト(#を行頭につける)して実行してください。
収集したツイートをjanomeで分かち書き
つぎに取得したテキストを、janomeライブラリで分かち書きにします。分かち書きというのは、文章を単語ごとに英単語のようにスペースで区切って分けることです。これによりWord Cloudでの解析をサポートします。
・janomeのインストール
> pip install janome
コードはこちらです。
ツイートを収集したテキストファイル(tweets.txt)と同じフォルダで実行してください。テキストを分かち書きにして、ファイル名「wakachi.txt」として保存します。
Word Cloudで出力
マスク画像を用意する
最後に好きなマスク画像を用意して、Word Cloudを適用します。白黒の画像ならなんでもOK!です。
JPG形式にして、「mask.jpg」というファイル名で保存してください。例として、出力結果の「LOVE」で使用したマスク画像はこちらです。

ソースコード
こちらの記事を参考に、前回つくったファイルを修正いたしました。
コードはこちらです。
- STOPWORDSで、除外したいキーワードを指定できます。
- contour_width、contour_colorは周りの線の太さと色です。
- colormapは色のテーマです。hotやwinterなどあります。以下の記事を参考になさるとよいかと思います。
matplotlib - カラーマップについて - Pynote
ライブラリのインストール
コードの実行には、ライブラリ「wordcloud」「NumPy」「pillow」が必要になります。
・wordcloudの導入は、以下を参考になさってください。
Word Cloud を導入する - hatebcustom Python入門③人気者のTwitterを画像化!インフルエンサーとは? - ハテブカスタム

rubirubi.hateblo.jp
NumPy、pillow は pipコマンドでインストールしてください。
NumPyは数値計算、Pillowは画像処理を効率的に行うためのライブラリです。
※なお、pip listですでにインストールしているライブラリの一覧が表示できます。
> pip install numpy > pip install pillow
PIL と pillow
PIL(Python Imaging Library)は、2011年に開発が停止した画像処理ライブラリです。PILの後継としてpillowが生まれました。
そのため、コードの2行目で「from PIL import Image」とPILの記載がありますが、同じ構文でpillowも読み込まれます。
また、PILとpillowは共存できませんので、新しいpillowをインストールしたほうがよいでしょう。
コードの実行
ツイートを分かち書きしたファイル(wakachi.txt)、用意したマスク画像(mask.jpg)の2ファイルと同じフォルダで実行してください。
出力結果
出力結果です。うまくいきました!
「Love」を含むツイート1000件
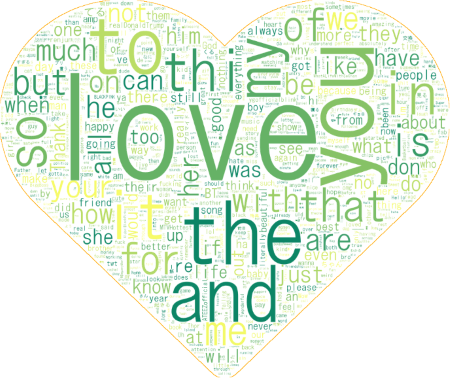
「吉本興業」を含むツイート1000件

吉本興業で大きめなのが、「宮迫 会見 岡本 社長」ですね・・。
・・・ここから余談を言います。
わたしはお笑い・吉本が大好きです。
ワイドナショーで松ちゃんが言ってたように、岡本社長が昔、ガキの使いでやってたみたいに宮迫さんと○首相撲とかやって、仲直りして、絆とか深まったらいいな、って思います。
しばらくは謹慎だろうけど、ロンブーの亮さんとか他の関係者のみなさんも、無事復帰してくれることを祈ります!
ホントに余談だったゴロ
動くWord Cloud
この記事の冒頭で動いてる文字ですが、「amCharts」というJavaScriptのチャートライブラリを利用しています。楽しいですよね!というJavaScriptのチャートライブラリを利用しています。楽しいですよね!
こちらが、デモです。
こちらから、CSSなどいろいろ編集してみてください。HTMLのテキストエリアの文章を変えれば、入れた文字が反映されます。 では、Twtter APIで「LOVE」というワードを含むツイートを取得して、形態素解析をかけたワードを入れています。…いろいろ遊んでみてください ٩(ˊᗜˋ*)و
それでは、今日はここで終わります。Word Cloudは面白い、ですね!
最後までお読みいただき、ありがとうございました。(^O^)/p>
参考図書

よろしければ、こちらの投稿もごらんください↓