Python入門②インフルエンサーとは?Twitterでふんわり分析

Pythonの勉強/インフルエンサーとは?
Twitterアカウントからスクレイピングで最近の200ツイートを抽出し、分析します。【Pythonでできること】
- Pythonでできること
- インフルエンサーとは
- 有名人のTwitterアカウントから、最近のツイートをスクレイピング
- スクレイピングしたツイートを、janomeで形態素解析
- Word Cloudで可視化
Pythonでできること
今回は、ひさびさにPythonを使って、何かやりたいと思いまして。
「Python」という言葉を、Ubersuggestでキーワード候補検索すると、、
- できること
- 入門
- 学習
- 勉強
などの言葉が候補のなかでSEO的に効果がありそうだったので、いつかどなたかに読んでもらえることを願って、、この辺の言葉をからめた内容で、考えてみることにします。
Ubersuggestは、無料のSEO対策ツールです。Ubersuggestを利用したブログタイトルの付けかたについては、こちらの記事を参照なさってください。rubirubi.hateblo.jp
「勉強」とか「学習」って、どうせなら流行ってるとか話題のモノ・人を題材にした方が楽しい!と思いまして。(正直、やってる本人もちょっと興味ありで。^_^; )
ですので、今回は、
芸能人など有名インフルエンサーの方々の最近のTwitterでのつぶやきをスクレイピングして、形態素解析でトレンドを知る
なんてことを、Pythonを学びながら、やってみようかと思います。
なんだか仰仰しくなってしまいましたが、形態素解析というのは、かんたんに言うと
”文を単語に分け、内容を判断する”
ことです。Googleなどの検索エンジンにも用いられています。
はてなブログの登録時の自動ジャンル分け機能も、形態素解析が用いられてる気がします。
流行にウトいわたしでも、トレンドな人の人となりが分かれば、流行りすたりも見えてくるのかな?って感じで。
あ、ちなみにスクレイピングというのは、ざっくり言うとプログラムでサイトなどの情報を収集・抽出すること、です。
Webスクレイピングって??
インフルエンサーとは
インフルエンサー、というワード自体わたし的にはあまり馴染みがなく、インフルエンザに似てるなぁぐらいにしか思ってなかったのですが。
ブログを始めて、よく目にするようになった印象があります。
インフルエンサー (英: influencer)は、世間に与える影響力が大きい行動を行う人物のこと。その様な人物の発信する情報を企業が活用して宣伝することをインフルエンサー・マーケティングと呼んでいる。
インフルエンサー - Wikipedia
なるほど。すでに2007年ごろから、ブログなどの影響で、広まってたみたいですね。
わたしは乃木坂46さんの歌でほとんど初めて聞いたくらいの言葉でした・・恥ずかしい。^_^;
新卒採用の指標にもなってるんですねー。
Ubersuggestで「インフルエンサー」をキーワード候補にかけると、11万のボリュームでした。↓
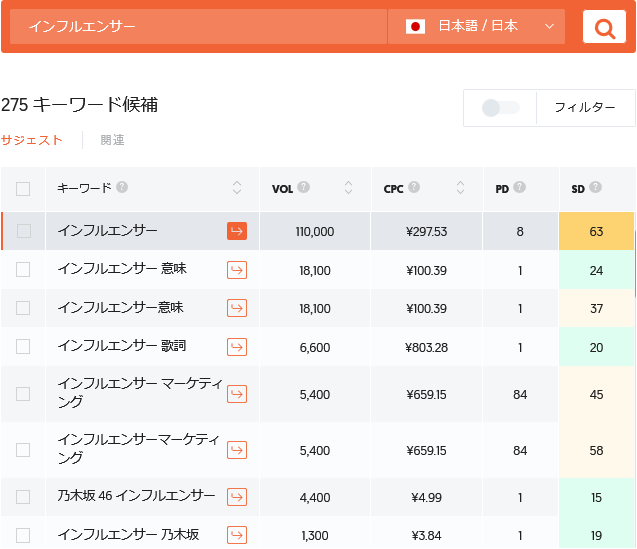
ちなみにWikipediaの英語版では、「Influencer」単体の説明はなく、「Influencer marketing(インフルエンサーマーケティング)」へのリンクが貼られているだけでした。そちらを読むと、何をもってインフルエンサーと呼ぶのかについては、いろいろな議論があり、定義があいまいな印象でした。
で。まず、最近日本で流行りのインフルエンサーさんを探してみました。
最新のインフルエンサーさんが知りたいので、期間を最近一か月以内にして、「インフルエンサー 2019」で、ググってみます。
すると、こんなページが上位表示されました。
インフルエンサーパワーランキング2019【上半期】|東海オンエアの勢いが止まらない!チャンネル総再生数、第1位!個人chもブラーボりょうが第1位!|株式会社BitStarのプレスリリース
トーカイオンエア?またも世間にウトいわたしなので、恥ずかしながら、まったくの初耳です。
愛知県を拠点としているYouTuberグループで、チャンネルの登録者がものすごい勢いで伸びてるらしいです。
それだけの人気者なら、どんなことをつぶやいてるのか、興味がありますね。
1人目のサンプルは、メンバーの中でも一番フォロワー数が多い、てつやさんに決めました。
そしてもう1人、同じページから人気モデルの藤田ニコルさんを選びました。
あとは、Twitterフォロワー数ランキング50から、独断と偏見で。
- 有吉弘行さん(1位)
- はじめしゃちょーさん(7位)
- 堀江貴文さん(12位)
- 孫正義さん(36位)
雨上がり宮迫さんは、33位なんですね。けっこう、人気あるんですね。関係ないですが・・。
そして50位圏外ですがこれも独断と偏見で、落合陽一さんと丸山穂高さん。
丸山さんは”インフルエンサー”とは趣が違うかも?ですが、世間に影響=世間を騒がすということにして、ムリヤリ仲間に加えました。(*^_^*)
以上8名の方々のつぶやきを、追ってみたいと思います!
有名人のTwitterアカウントから、最近のツイートをスクレイピング
ここからPythonとTwitterを連携して、ツイートを取得していきます。
そのためには、
- Pythonを使うための準備
- Twitter APIを利用するための承認
が必要です。
Pythonを使うには?
Twitteer APIの承認
Twitter API利用の承認は、ちょっと手間です。こちらの記事に親切にまとめられているので、参考になさってください。
Twitter API 登録 (アカウント申請方法) から承認されるまでの手順まとめ - Qiita
アドバイスになるか、わかりませんが。
とりあえずわたしは、ブログやTwitter、Rubyで作ったアプリなどのリンクを貼り、こんなことをやっていて、プログラム学習のためにAPIを利用したいです!的なことを書きました。
Twitter側と英語によるメールのやりとりが必要なのですが、Google翻訳や、他の方のブログなどを参考にすれば、ある程度、文章は作れると思います。
ヘタな英語でも意味が通じればいいと思うので。たぶん。
あとはところどころ自分にあった内容に変えてやれば、2~3回くらいのメールのやりとりで、イケる・・はずです。責任は持てません、あしからず<m(__)m>
でも、もしよかったら、チャレンジしてみてください。
Twitter APIが使えると、できることも広がって、Pythonの勉強が楽しくなると思うので、個人的には登録をオススメします(^_-)-☆
とりあえずわたしは、ブログやTwitter、Rubyで作ったアプリなどのリンクを貼り、こんなことをやっていて、プログラム学習のためにAPIを利用したいです!的なことを書きました。
Twitter側と英語によるメールのやりとりが必要なのですが、Google翻訳や、他の方のブログなどを参考にすれば、ある程度、文章は作れると思います。
ヘタな英語でも意味が通じればいいと思うので。たぶん。
あとはところどころ自分にあった内容に変えてやれば、2~3回くらいのメールのやりとりで、イケる・・はずです。責任は持てません、あしからず<m(__)m>
でも、もしよかったら、チャレンジしてみてください。
Twitter APIが使えると、できることも広がって、Pythonの勉強が楽しくなると思うので、個人的には登録をオススメします(^_-)-☆
コードの使い方
Twitter APIの利用申請が通れば、モジュール「tweepy」をインポートして利用できますので、コマンドプロンプト(Macだとターミナル)からpipコマンドでtweepyをインストールしてください。
> pip install tweepy
Pythonのコードです。
1行目の下記のコードでtweepyを呼び出しています。
import tweepy
[Twitter Developper > apps > keys and tokens] からキーを取得し、コードの指定位置に貼り付けてください。
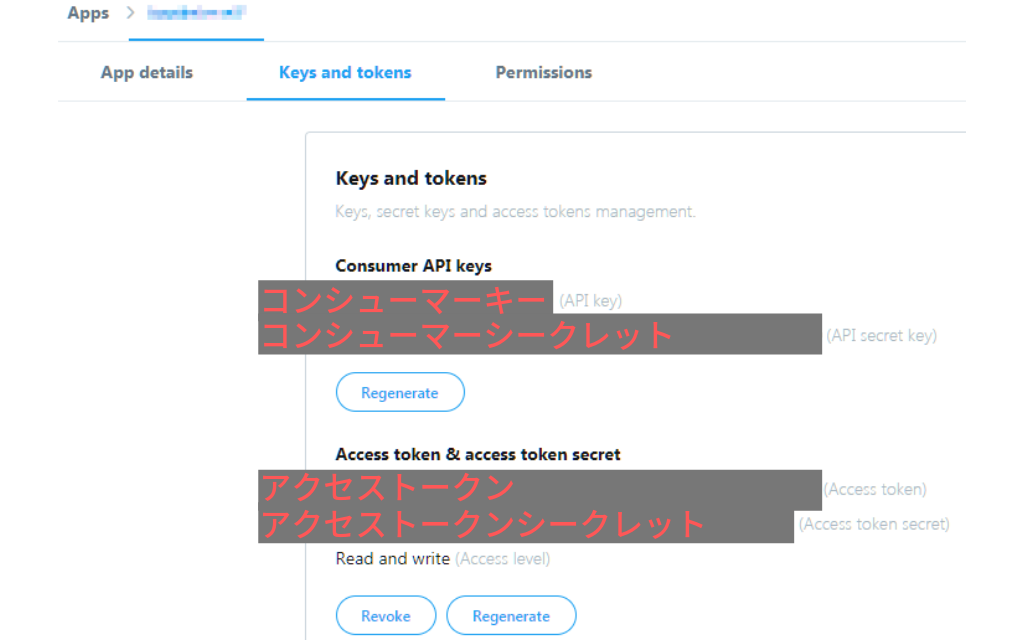
3 CK = "コンシューマーキー"
4 CS = "コンシューマーシークレット"
5 AT = "アクセストークン"
6 AS = "アクセストークンシークレット"
Twitterアカウントの貼り付け
ツイートを取得したいTwitterのアカウントIDから”@”を除いた部分を、コードの一番下の指定位置に貼り付けてください。
たとえば、わたしのTwitterアカウントIDは「@heureux_yoppy」ですが、その場合は@を除いた「heureux_yoppy」を貼り付けます。
25 get_timeline(id="heureux_yoppy", count=200)
これで、準備ができました。
コードを「.py」のPython形式でファイルに保存し、Pythonファイルを実行すると、指定したアカウントユーザーの直近200ツイートを、実行ファイルと同じ場所に「tweets.txt」として保存します。
コマンドラインから実行するときは、下記のようにpythonコマンドを使います。
> python ファイル名.py
実行した結果がこちらです。下記は、孫正義さんのツイートです。

※tweepyを利用する際は、情報を取得する方式に決まりがあります。こちらは日本語訳されたドキュメントです。
Tweepyドキュメント — tweepy 3.6.0 ドキュメント
スクレイピングしたツイートを、janomeで形態素解析
つぎに、取得したツイートをPythonライブラリの”janome”で形態素解析します。janomeは、"Mecab"と並ぶ形態素解析の代表的なライブラリです。Mecabにくらべると実行速度は落ちますが、Pythonだけで記述されているため、pipコマンドでかんたんに導入できるメリットがあります。
> pip install janome
ソースコードはこちらです。
このコードを「.py」のPython形式でファイルに保存し、さきほど保存した「tweets.txt」と同一ディレクトリに置いて実行してください。
> python ファイル名.py
こちらは、藤田ニコルさんの出力結果です。
藤田 ニコル(にこるん) @0220nicoleの解析結果
うーーん・・。「https」や「@」マークなど、不要なデータがありますね・・・。他にも記号や"てにをは”などの接続詞も、除外した形で出力した方が、いいかもしれません・・。ここは改善の余地(だいぶ)アリ、です。
内容的には、女の子っぽい、かわいい単語が並んでます。いかにもらしい、結果ですね。
つづいて、堀江貴文さんを、出力してみました。
藤田さんのは、わりと標準的というか、普通な感じ?だったので、今度はもっと頻度の少ない単語も見るため、抽出数を300語に増やしました。
コード27行目の”keys[:100]”の数値(100の部分)が抽出数なので、ここを変えれば変更できます。
27 for word,cnt in keys[:100]:
堀江貴文(Takafumi Horie) @takapon_jpの解析結果
堀江さんは個性出てますね(笑。「ハッタリ」が、86回でトップです。バカは4回でした。以外と少ない印象。下位の方が、個性が出るかも、ですね。
Word Cloudで可視化
ちょっとここで一旦、作業を中断します。勝手ですが。。(・・。)ゞ
わたしは分析のエキスパートではないので、このまま単語を並べてふんわり分析してても独断と偏見に過ぎません。※人選からすでにそうなんですが^_^;
もう少し、単純でわかりやすく結果を表現できる方法はないものか・・。と、いうことで、この続きは次回、こちら!に挑戦してみたいと考えました。

「Word Cloud」。テーマは"可視化"です。
抽出したツイートデータを見える化して、その人となりが一目でわかるような画像に変換する。
うまくいけば、インフルエンサーとは?のこたえをツイート分析で出せたことになるのではないでしょうか?(^u^)ウム!
わたしのスキルでできるのか・・一番の不安は、そこなのですが。
形態素解析は日本語に不向きなのかもしれませんね。やってみて、英語とちがって、単語化がむずかしいと、思いました。
読んでくれた同じ初心者の方の励みになるよう、無事成功させて、なるべくわかりやすい解説ができるように、がんばってみます!
↓つづきの記事は、こちらです↓
と、いう訳で、今日はここまでにします。
ここまで読んでいただき、ありがとうございました。(*^。^*)
どなたかの、お役にたてますように♪